 I’m so sick of the universal answer to all SEO questions. Each and every search engine rep keeps telling me that “creating a great and useful site with compelling content will gain me all the rankings I deserve”. What a pile of bullshit. Nothing ranks without strong links. I deserve more, and certainly involving less work.
I’m so sick of the universal answer to all SEO questions. Each and every search engine rep keeps telling me that “creating a great and useful site with compelling content will gain me all the rankings I deserve”. What a pile of bullshit. Nothing ranks without strong links. I deserve more, and certainly involving less work.
Honestly, why the heck should I invest any amount of time and even money to make others happy? It’s totally absurd to put up a great site with compelling content that’s easy to navigate and all that, just to please an ungrateful crowd of anonymous users! What a crappy concept. I don’t buy it.
I create websites for the sole purpose of making money, and lots of green. It’s all about ME! Here I said it. Now pull out the plastic. 
And there’s another statement that really annoys me: “make sites for users, not for search engines”. Again, with self-serving commandments like this one search engine quality guidelines do insult my intelligence. Why should I make even a single Web page for search engines? Google, Yahoo Microsoft and Ask staff might all be wealthy folks, but from my experience they don’t purchase much porn on-line.
I create and publish Web contents to laugh all the way to the bank at the end of the day. For no other reason. I swear. To finally end the ridiculous discussion of utterly useless and totally misleading search engine guidelines, I’ll guide you step by step through a few elements of a successful website, explaining why and for whom I perform whatever, why it’s totally selfish, and what it’s worth.
In some cases that’ll be quite a bit geeky, so just skip the technical stuff if you’re a plain Internet marketer. Also, I don’t do everything by the book on Web development, so please read the invisible fine print carefully .
robots.txt
This gatekeeper prevents my sites from useless bot traffic. That goes for behaving bots at least. Others might meet a script that handles them with care. I’d rather serve human users bigger ads than wasting bandwidth for useless bots requesting shitloads of content.
.htaccess
I’m a big fan of the “one URI = one piece of content” principle. I consider gazillions of URI variations serving similar contents avoidable crap. That’s because I can’t remember complex URIs stuffed with tracking parameters and other superfluous clutter. Like the average bookmarking surfer, I prefer short and meaningful URIs. With a few simple .htaccess directives I make sure that everybody gets the requested piece of content advertising under the canonical URI.
ErrorDocuments
Error handling is important. Before I throw a 404-Not-found error to a human visitor, I analyze the request’s context (e.g. REQUEST_URI, HTTP_REFERER). If possible, I redirect the user to the page s/he should have requested then, or at least to a page with related links banner ads. Bouncing punters don’t make me any money.
There’s more than HTTP response codes doable with creative headers. For example cost savings. In some cases a single line of text in an HTTP header tells the user agent more than a bunch of markup.
Sensible page titles and summaries
There’s nothing better to instantly catch the user’s interest than a prominent page title, followed by a short and nicely formatted summary that the average reader can skim in few seconds. Fast loading and eye-catching graphics can do wonders, too. Just in case someone’s scraping bookmarking my stuff, I duplicate my titles into usually invisible TITLE elements, and provide seducing calls for action in descriptive META elements. Keeping the visitor interested for more than a few seconds results in monetary opportunities.
Unique content
Writing unique, compelling, and maybe even witty product descriptions increases my sales. Those are even more attractive when I add neat stuff that’s not available from the vendor’s data feed (I don’t mean free shipping, that’s plain silly). A good (linkworthy) product page comes with practical use cases and/or otherwise well presented, not too longish outlined, USPs. Producers as well as distributors do suck at this task.
User generated content
Besides faked testimonials and the usual stuff, asking vistors questions like “Just in case you buy product X here, what will you actually do with it? How will you use it? Whom will you give it to?” leads to unique text snippets creating needs. Of course all user generated content gets moderated.
Ajax’ed “Buy now” widgets
Most probably a punter who has clicked the “add to shopping cart” link on a page nicely gathering quite a few products will not buy another one of them, if the mouse click invokes a POST request of the shopping cart script requiring a full round trip to the server. Out of sight, out of mind.
Sitemaps
Both static as well as dynamically themed sitemap pages funnel a fair amount of vistors to appropriate landing pages. Dumping major parts of a site’s structure in XML format attracts traffic, too. There’s no such thing as bad traffic, just weak upselling procedures.
…
Ok, that’s enough examples to bring my point home. Probably I’ve bored you to death anyway. You see, whatever I do as a site owner, I do it only for myself (inevitably accepting collateral damage like satisfied punters and compliance to search engine quality guidelines). Recap: I don’t need no stinkin’ advice restrictions from search engines.
Seriously, since you’re still awake and following my long-winded gobbledygook, here’s a goodie:
The Number One SEO Secret
Think like a search engine engineer. Why? Because search engines are as selfish as you are, or at least as you should be.
In order to make money from advertising, search engines need boatloads of traffic every second, 24/7/365. Since there are only so many searchers populating this planet, search engines rely on recurring traffic. Sounds like a pretty good reason to provide relevant search results, doesn’t it?
That’s why search engines develop high sophisticated algorithms that try to emulate human surfers, supposed to extract the most useful content from the Web’s vast litter boxes. Their engineers tweak those algos on a daily basis, factoring in judgements of more and more signals as communities, services, opportunities, behavior, and techniques used on the Web evolve.
They try really hard to provide their users with the cream of the crop. However, SE engineers are just humans like you and me, therefore their awesome algos -as well as the underlying concepts- can fail. So don’t analyze too many SERPs to figure out how a SE engineer might tick, just be pragmatic and imagine you’ve got enough SE shares to temporarily throw away your Internet marketer hat.
Anytime when you have to make a desicion on content, design, navigation or whatever, switch to search engine engineer mode and ask yourself questions like “does this enhance the visitor’s surfing experience?”, “would I as a user appreciate this?” or simply “would I buy this?”. (Of course, instead of emulating an imaginary SE engineer, you also could switch to plain user mode. The downside of the latter brain emulation is, unfortunately, that especially geeks tend to trust the former more easily.)
Bear in mind that even if search engines don’t cover particular (optimization) techniques today, they might do so tomorrow. The same goes for newish forms of content presentation etc. Eventually search engines will find a way to work with any signal. Most of our neat little tricks bypassing today’s spam filters will stop working some day.
After completing this sanity check, heal your schizophrenia and evaluate whether it will make you money or not. Eventually, that’s the goal.
By the way, the above said doean’t mean that only so-called ‘purely white hat’ traffic optimization techniques work with search engines. Actually, SEO = hex’53454F’, and that’s a pretty dark gray. 
Related thoughts: Optimize for user experience, but keep the engines in mind. Misleading some folks just like this pamphlet.
Share/bookmark this: del.icio.us •
Google •
ma.gnolia •
Mixx •
Netscape •
reddit •
Sphinn •
Squidoo •
StumbleUpon •
Yahoo MyWeb
Subscribe to  Entries Comments All Comments Entries Comments All Comments
|
|
|
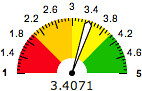
 Of course localization is in place and working fine (you can change your current address in your Google Profile at any time by providing Checkout with another credit card).
Of course localization is in place and working fine (you can change your current address in your Google Profile at any time by providing Checkout with another credit card). Press the Search button.
Press the Search button. Now tell the almighty Google why your pathetic site deserves better rankings than the popular brands with deep pockets you’re competiting with on the Interwebs.
Now tell the almighty Google why your pathetic site deserves better rankings than the popular brands with deep pockets you’re competiting with on the Interwebs. Today I’ve removed all instances of the thunderbird icon from my computers, and from my memory as well. I’m finally done with email. I’ve forwarded
Today I’ve removed all instances of the thunderbird icon from my computers, and from my memory as well. I’m finally done with email. I’ve forwarded



 … I just have to link to North South Media’s neat collection of Search Action Figures.
… I just have to link to North South Media’s neat collection of Search Action Figures.  Recently
Recently  I’m truly excited. Two of my pamphlets made it in The Rubber Chicken Award’s Top 10! That’s 50% success (2/4 nominated pamphlets), so please help me to make that 100%: vote for #3 and #4!
I’m truly excited. Two of my pamphlets made it in The Rubber Chicken Award’s Top 10! That’s 50% success (2/4 nominated pamphlets), so please help me to make that 100%: vote for #3 and #4! 

 Blogging should be fun every now and then. Today I don’t tell you anything new about Google’s secret experiments with the robots exclusion protocol. I ask you instead, because I’m sure you know your stuff. Unfortunately, the Q&A on undocumented robots.txt syntax from Google’s labs utilizes JavaScript, so perhaps it looks somewhat weird in your feed reader.
Blogging should be fun every now and then. Today I don’t tell you anything new about Google’s secret experiments with the robots exclusion protocol. I ask you instead, because I’m sure you know your stuff. Unfortunately, the Q&A on undocumented robots.txt syntax from Google’s labs utilizes JavaScript, so perhaps it looks somewhat weird in your feed reader. 